Research Deliberation
Overview
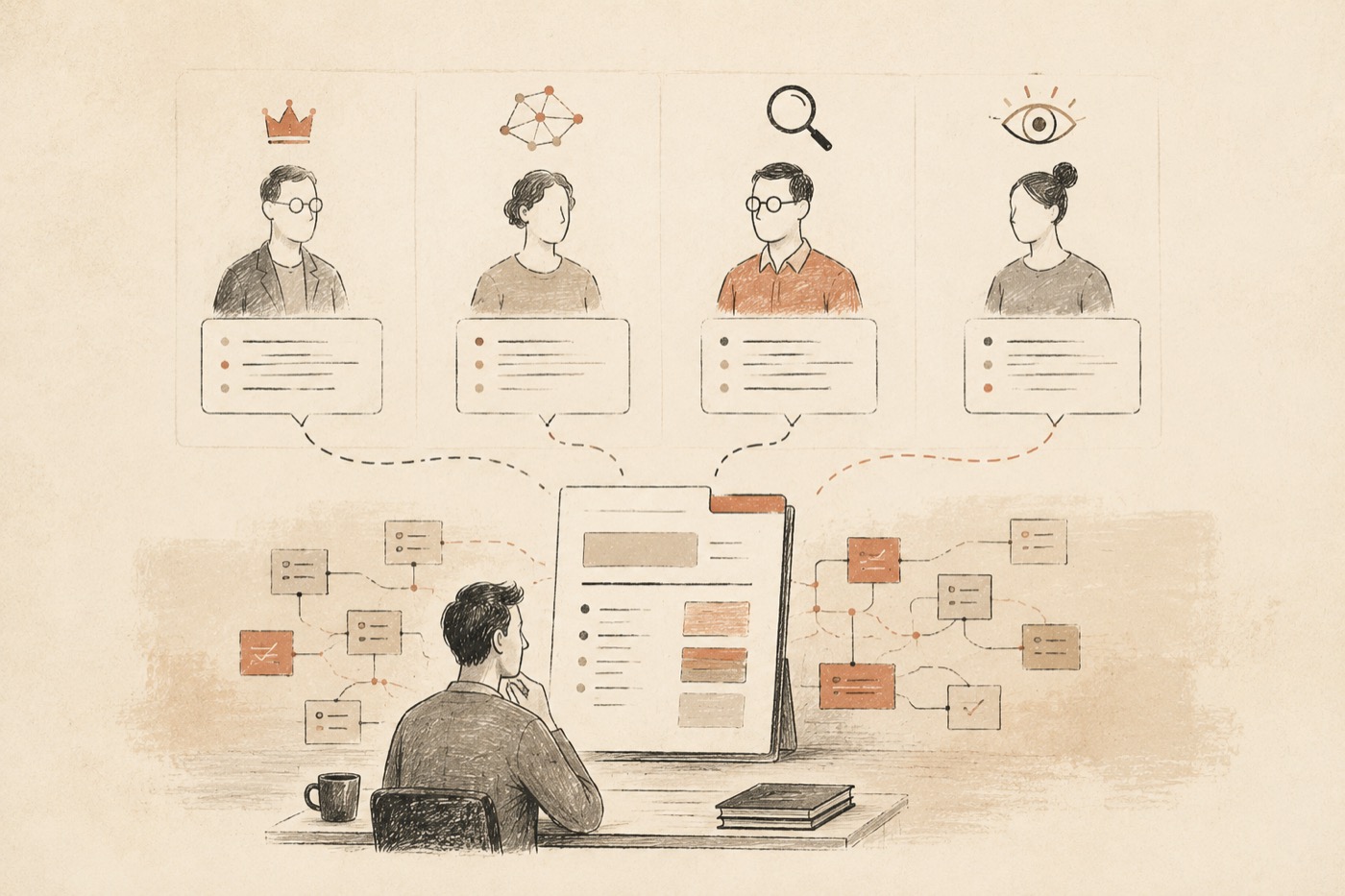
Research Deliberation is an AI pre-review system for researchers in the humanities and social sciences. It takes a research proposal or design and subjects it to four independent reviewer perspectives — a lead researcher, a broad-field peer, a specialist peer, and a journal blind reviewer — each operating with its own context boundary. Instead of generating a single summary, it produces a layered Research Review Packet: a decision brief up top, problem cards in the middle, and four full expert memos with an evidence appendix for anyone who wants to go deeper.
The project began with a simple question: can AI critique a research idea without defaulting to the first opinion it forms? Three rounds of evaluation across five cross-method test cases — and one real PhD researcher — showed that the answer depends less on how many roles you name and more on whether those roles are actually free to disagree.
The Problem
Early-career researchers in the humanities and social sciences face a structural problem: they need critical feedback on their research designs, but the people around them are either too busy, too polite, or too similar in perspective. Advisors have limited time. Peers hesitate to challenge. And general-purpose AI tools, while helpful for summaries and polish, tend to mirror the researcher's own framing rather than expose its weak points.
One doctoral researcher I interviewed put it plainly: "I don't want the AI to become another me." She had used a frontier model to review her proposal and received ten suggestions — specific, reasonable, and oddly reassuring. But by the time she acted on the third one, she suspected the first two had been wrong. The model had been thorough without being independent. What she needed wasn't more feedback. She needed to know which problems shared a root cause, which one to fix first, and whether the project was fundamentally sound or needed rethinking — and she needed that judgment to be traceable back to evidence, not asserted as a conclusion.
Product Judgment
Three convictions shaped the product.
First, external perspective is the product. The system's job isn't to agree with the researcher or to optimize for reassurance. It's to surface provably independent judgment. That means reviewers must not see each other's conclusions before forming their own, and the editor at the end must preserve disagreement rather than synthesize it away.
Second, a strong baseline is non-negotiable. Frontier models already produce reasonable academic feedback. If a multi-agent system can't demonstrate clear, measurable improvement over a single well-prompted model, it hasn't earned its complexity. Every architectural decision was tested against a bare-model baseline using the same inputs and the same rubric.
Third, the deliverable is not a report — it's a decision tool. Researchers don't need another document to read linearly. They need to know, within minutes: is this project viable? What are the three most dangerous problems? Which ones are connected? And when they're ready, they need to drill into specific reviewer reasoning with evidence they can verify. The Research Review Packet is designed for that progressive disclosure.
How It Works
Four independent reviewer agents each receive the same research material but operate within separate context windows. They cannot see each other's conclusions, and the editor only aggregates after all four have submitted.
Lead Researcher identifies root causes, traces causal chains between problems, and judges whether the project holds together. Broad-Field Peer assesses theoretical significance, checks whether case novelty is being mistaken for contribution, and positions the work in a larger field conversation. Specialist Peer verifies concepts and key literature, cross-checks data choices against domain conventions, and flags missing methodological context. Journal Blind Reviewer formulates the strongest case for rejection, classifies issues as Fatal / Major / Moderate, and specifies what would remove each objection.
The pipeline runs: intake → diagnosis → four parallel peer reviews → verification of high-risk claims → aggregation into a layered Research Review Packet. Each agent operates with explicit stop conditions and a bounded task scope. If a reviewer fails or times out, the system degrades gracefully rather than fabricating a complete-looking output.
What I Tested
I built a five-case test set spanning mixed methods, qualitative interviews, historical archives, cross-sectional quantitative analysis, and an educational experiment. Four of the five were synthetic cases with pre-planted hidden answer keys — problems I embedded before generation that the model couldn't see — allowing objective measurement of problem recall.
The evaluation rubric went through three iterations with input from two doctoral researchers and one associate professor, eventually converging on a seven-dimension framework weighted toward core problem coverage, accuracy, and reasoning depth. Every version of the system was scored against a bare-model baseline on the same cases with the same rubric.
Testing wasn't a single pass. I ran four evaluation stages: baseline measurement, product increment assessment, regression testing after architecture changes, and finally a controlled ablation comparing shared-context vs. isolated-context reviewers. The isolated-context architecture scored 92.7 on a heuristic composite against the bare model's 77.3 across four comparable cases. Then I handed both outputs — bare model and full packet — to a real doctoral researcher and two human experts for blind comparison.
What Failed and Changed
The first version wrote four reviewer roles into a single prompt context. It scored slightly above baseline on average but actually performed worse on the metric that mattered most — core academic judgment — and missed the most important historical breakpoint in the archives case entirely. The reviewers were paraphrasing each other under different names.
The second version tried to fix this by protecting the lead reviewer's judgment as an unbreakable backbone. It backfired. When the lead was right, the backbone helped. When the lead was wrong — still missing that same 1945–1949 institutional transition — the backbone amplified the error and the whole system regressed below baseline.
The third version abandoned the shared-context approach entirely. Each reviewer became an independent sub-agent with its own context window, own task boundary, and no access to other reviewers' conclusions before submission. The editor's job shifted from synthesizing consensus to surfacing agreement and disagreement honestly. The archives case — the one that had broken both earlier versions — was now flagged as Fatal. More importantly, I could point to exactly which reviewer caught it and why.
The delivery format went through a parallel transformation. When all four reviews were compressed into one summary, the independence gained at the agent level was lost again at the reader level. The layered Research Review Packet was the answer: don't flatten depth, structure access to it.
Current Limits
Only one real doctoral researcher has completed a controlled comparison of the bare model vs. the full packet, supplemented by two expert reviews from her advisor and a senior peer. That's real signal, but it's not a systematic user study. Four of five test cases are synthetic — designed with hidden answer keys for objectivity, but not a substitute for real proposals. The scoring uses an LLM-as-Judge with human audit, and inter-rater reliability hasn't been formally measured. The V3 architecture used more inference budget than the baseline; an equal-token ablation hasn't been run, so the precise contribution of context isolation vs. additional compute isn't yet isolated.
Technical Debt
A formal ablation study — equal tokens, equal cost, architecture as the only variable — hasn't been conducted. The system uses a four-level degradation strategy when components fail, but cross-runtime degradation hasn't been systematically tested. And the multi-agent contribution isn't yet decomposed: independence, reasoning budget, and output length all increased together in V3, and their individual effects aren't separated.
These are the kind of debts a project accumulates when you're the only person building, testing, and writing. They're documented so the next person — or future me — knows exactly where to start.
Next Step
The architecture is stable and the evaluation results are documented. Three questions are worth answering next.
Can a thin frontend reduce the reading burden from two hours to something closer to ten minutes — not by shortening the reviews, but by structuring navigation through them? When context isolation is isolated as the only variable in an equal-token ablation, does the effect hold? And if the system collects a researcher's actual constraints — time, skill, data access — at intake, do its recommendations become more actionable without becoming less ambitious?
These are the questions that turn a prototype into a product. The answers will come from the same method that got the project this far: test against a baseline, measure honestly, and change the architecture when the evidence says to.